{kind=link}
All content is available under Creative Commons
Attribution-ShareAlike license unless specified otherwise.
Attribute by linking.
The views and opinions are not necessary of my current or
past affiliations, nor are they necessary mine.
Not everything I write or share I agree with, e.g.,
it can be hypothetical, to provoke debate, troll, play devil's advocate,
entertain half-baked ideas,
explore new lines of thought or perspectives.
Not everything I expressed in the past I agree with today.
Linking is not endorsement.
All feedback is welcome.
He/him.
Mitar's Point
Somewhere and everywhere between (computer)
science, technology, nature and (open) society.
science, technology, nature and (open) society.
Contact
Speech recognition
I do not know much about speech recognition. I do not know what is the state of the art. But years ago I was playing a bit with it and I would like to throw an idea our there, maybe somebody picks it up, maybe it turns out useful, or maybe it is already being used. Please tell me. It can be used for not just speech recognition, but any general audio pattern recognition, or any signal pattern recognition.
The basic idea is to observe that human hearing works by first cochlea doing physically a frequency transform. Hairs of different lengths resonate to frequencies in the audio input. Stronger a particular frequency is in the input, stronger will be a signal for that hair. A stronger signal in neurons does not mean a larger amplitude of the action potential, but more of them. So a stronger signal for a particular frequency means that more impulses will go over that neuron. More impulses mean a higher frequency of those impulses. So brain has to learn not directly from the input audio, but from changes of frequency of the signal for each frequency in the input audio. If brain is recognizing patterns from that, we should too.
A common way to analyze signals is to do a frequency transform and try to learn about properties of the signal from there. But the issue is that most signals change through time, including speech, but a frequency transform tells us just an average presence of frequencies at the interval we are looking at. There are other ways how are people trying to address this and they might be compatible with my idea, but to keep it simple we will just use a basic frequency transform as a primitive.
We can take a small interval window (which window function exactly is another parameter here) and slide it through the input signal and compute frequencies as we are sliding. We can visualize the result for an audio of few spoken vowels into the following spectrogram.
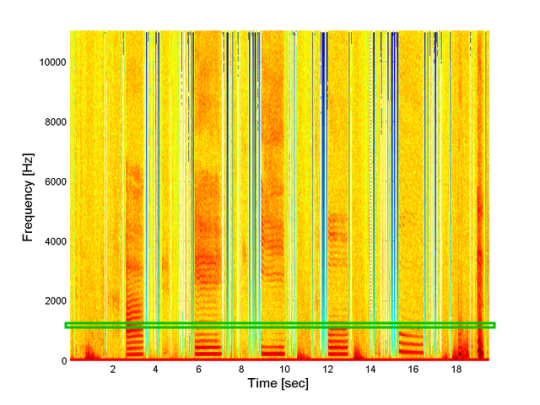
But we can also move a window very slowly, sample by sample in the original input audio. Then we get for each frequency a new signal corresponding to how this particular frequency has been changing on average inside this window (I used a 30 ms long rectangular window). An example of such new signal is depicted with green border on the spectrogram above. Now, to use my idea, we run a frequency transform on these signals for each frequency again. As a result we get for each frequency in the input audio what are frequencies of changes of that frequency. To me this is similar to a derivative of a derivative, a second derivative.
As na experiment, I ran this on recordings of individual speech sounds. In this case I simply computed the second frequency transform over the whole new signal for each input frequency. But we could be doing windowing and sliding again, to determine how sounds are changing through time.
When doing a series of such transforms we hit against a problem of frequency resolution vs. time resolution. Shorter the window is, higher time resolution we have, but less frequency resolution we have. For speech we are interested only in a short frequency band inside which humans speak, so we could use different ways to get good frequency resolution at that band, but I simply used recordings made at a 192 kHz sample rate which provided me with more samples so I was able to have a 30 ms window but still reasonable frequency resolution.
For each of multiple samples per sound I made a double transform and visualized results below. On Y axis we have various frequencies from the input (oriented the same as in the spectrogram above, but just band around human speech shown), and on X axis we have power of each frequency of frequency, starting from the left. It seems changes to frequencies are itself at a very low frequency so I am showing only low frequencies. Each image continues far to the right, but does not contain anything visible there.
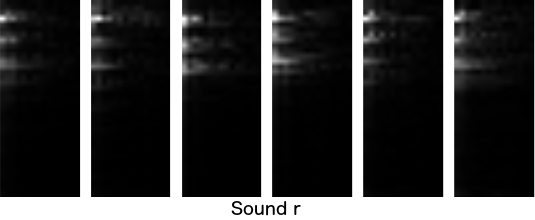
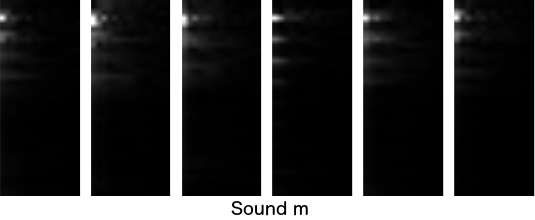
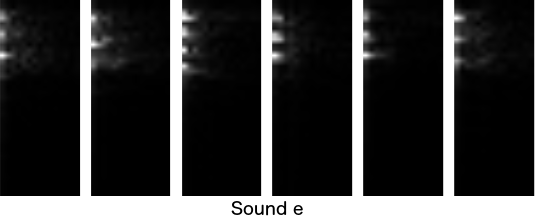


Visually, they look pretty similar to each other when comparing the same sound, and nicely different when comparing across sounds. This is great! This gives us 555 values (37x15) we can feed into a pattern recognition algorithm. Deep learning or something similar. I will leave to somebody else to test deep learning on this and to determine how to upgrade this one sound recognition to speech recognition when sounds are changing through time. Good luck!
Attributions: vowel spectrogram