All content is available under Creative Commons
Attribution-ShareAlike license unless specified otherwise.
Attribute by linking.
The views and opinions are not necessary of my current or
past affiliations, nor are they necessary mine.
Not everything I write or share I agree with, e.g.,
it can be hypothetical, to provoke debate, troll, play devil's advocate,
entertain half-baked ideas,
explore new lines of thought or perspectives.
Not everything I expressed in the past I agree with today.
Linking is not endorsement.
All feedback is welcome.
He/him.
Mitar's Point
Somewhere and everywhere between (computer)
science, technology, nature and (open) society.
science, technology, nature and (open) society.
Contact
Towards layered re-decentralized web
Re-decentralizing web and Internet-based technologies is gaining momentum. Just recently there was a Decentralized Web Summit where many projects were represented. But while people contemplate importance of decentralized technologies and are building alternatives, to me it seems we are forgetting one important lecture from the past: we should be building layered technological stacks and not vertically integrated ones. This is how you can encourage diverse implementations (critical for stability of decentralized technologies) and experimentation at each layer without having to reimplement a whole stack. I can understand why this is happening. It is already hard enough to develop decentralized technologies. So it feels easier to control the stack at least vertically. But we should not be building decentralized technologies because it is easy. But because it is hard.
Decentralized and permanent web
From the perspective of a human civilization current world wide web is broken. It has evolved from serving static content into dynamic app-based services. And while static content is based on open standards which can be easily preserved for future generations, dynamic content requires service providers to stay online forever. There is no way to archive services and preserve them for current or future generations. Architectures of those services simply do not support that. And for success of any civilization it is vitally important to be able to preserve its history.
Web as we know it today, as explained by the Mozilla’s Mitchell Baker at the Decentralized Web Summit, is:
- Immediate. Safe instant access to content accessible via a universal address without the need for install.
- Open. Anyone can publish any content without permission or barrier and provide access as they see fit.
- Universal. Content runs on any device on any platform.
- Agency. User agent can choose how to interpret content provided by a service offering.
But users are not really in control. Service providers today can decide and deny a service to the user, they can terminate their service, change it without user’s consent. User’s rely on service providers for their security. A compromised service provider also compromises all their users.
Even if a developer wants to build a web app where user would be in power, it is not possible to do so with currently widely available technologies. The main reason is that such solution has to be done by multiple parties. Like web itself does not really bring much advantage if there is only one web server in existence, permanent web works when there are multiple developers using it for their apps and services, providing to each other necessary infrastructure to assure apps stay available forever. For permanent world wide web applications, once content, an app, or a service is deployed it should stay available while there is at least one user using it (maybe just a librarian). And not only while a service provider cares about an app.
There are many existing projects working in this space: IPFS, WebTorrent, BigchainDB, Ethereum, Matrix, Tendermint, Blockstack, SwellRT, Scuttlebot, and many others. But while all these are all great projects to explore the design space of modern decentralized technologies, the power of decentralization is not in the fact that one system manages to decentralize itself, or that we create one decentralized architecture to rule them all, but that we have decentralized layers which empower each other and mix use cases to make a robust ecosystem.
For example, Bitcoin uses its own P2P data-exchange network at the lowest layer. This means that any attack on the P2P network is an attack only on Bitcoin and has no other side effects an attacker might dislike. Moreover, the only reason and incentive users have to participate in this P2P network is to participate in the cryptocurrency, so the networks userbase is limited only to those users.
On the other hand, users of Tor network are diverse. Different people are using the network for different reasons. Even governments are using Tor network. Trying to limit one use of the network interferes with other uses. Trying to limit some users limits other users as well. Diversity in users and use cases makes Tor strong. This makes Internet and web strong. But we lack this in our decentralized technologies we are building.
Decentralized and layered
We should be building our technologies according to the following design principles, which were used also for Internet itself:
- The end-to-end principle.
- Optimize for flexibility.
- No barriers to entry. No gatekeepers. Low investment to join or start participating.
- Make it easy to try. Fault tolerance.
- Build an ecosystem. Distributed coordination.
The architecture should be decentralized but also layered. For example, we could try to organize new technologies mentioned above into a stack like:
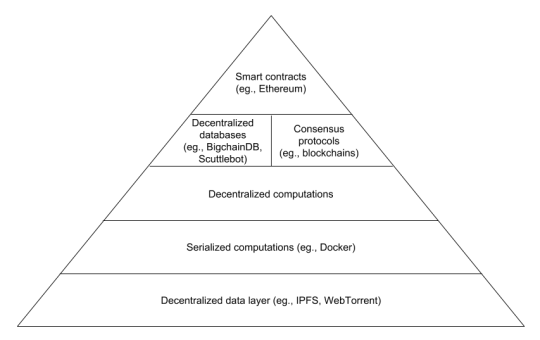
Those layers could be split into even smaller layers (IPFS itself is, for example, split into many smaller layers).
Such architecture is of course harder to build. You have to design interfaces between layers well. You have to talk to and coordinate with other projects. You have to establish standards. But it allows more innovation: one can just innovate in one layer and reuse others. I am not talking here about code reuse. We can have layers nicely each in its own code module and then you can change code of only one layer to experiment. This is nice, a requirement, but this is not it. We want to have other layers running as they are, deployed. When I create a new web application, I do not have to re-deploy the whole Internet stack and get users to use my new stack (even if it happens to share code with other stacks based on the same codebase). Other layers simply keep running and supporting my new app as well. This allows me to innovate only inside one layer and reuse existence and adoption of other layers directly.
Besides improving potential for innovation such architecture improves robustness of the ecosystem as well. Let us look at smart contracts as a target application in the pyramid above, as an example. Instead of developing smart contracts in its own stack, we could be reusing layers running for other purposes. decentralized data layer would not be used only for storing blocks of transactions, but also for distributing files, static web content, archiving the web, distributing scientific data sets and so on. Decentralized computations could run any type of computations, a background worker for a decentralized web application, a CGI rendering for a new movie, protein folding, etc. Some databases on top of those computations might not care about consensus of the data. They might just want to store all data and allow queries on top. But some might care about consensus. Some in a permissioned setting where you exactly know who the users are and can use BFT protocols. Some in permissionless setting using some type of proof of work to resolve the consensus. An interesting thing is that by using a general data layer, you can commit to the new block locally, for example, add it to your local IPFS instance, and if your block wins, only then everyone asks for it and the block gets distributed among all participants in the consensus layer.
Smart contracts can then be seen just a special case of those generic computations on top of a consensus-based decentralized database. Which can access also all other layers as needed, not just transactions, but for example a rendered movie, to detect if a payment has to be made for a finished rendering service. It can leverage other layers and capabilities there as well.
This makes the whole ecosystem much more robust and diverse. A specialized attack on one use case can be mitigated by other use cases. A general attack has potential side-effects you are not willing to do. For example, if incentivization issue is discovered for smart contracts which makes users not willing to run smart contracts of others, users who are participating at the decentralized computation layer and are not part of smart contracts users would still continue running them, maybe just to gain their own “CPU credits” inside the decentralized computation layer. It would be much harder to game the system and find disruptive strategy because you would have actors in the system with various backgrounds, values, and incentives.
On the other hand, if somebody would like to disrupt the data sharing layer because they want to censor some content there, they might discover that this disrupts the whole financial sector as well, build on top of smart contracts on top of this stack. This might make them less willing to attack the data layer.
There is strength and power in diversity. We should be building towards that.
Decentralized computations layer
The missing layer seems to be this decentralized computation layers for general computations. An ultimate virtual machine, if you wish. But necessary pieces might already be there. First, we just have to store code for computations in some serialized way on the data layer. This might be simply reusing Docker images, or even just a JavaScript code string to run inside node.js or something. Or all of those, supporting various languages and binaries. Probably we would require that computations are pure and deterministic, not allowing to call any system calls. On top of those serialized computations a decentralized set of participating workers would run those serialized computations every time new data input is available for them, storing the result. How data input is made available depends on a particular design, but we could imagine some pub/sub approach which can take data from any other layer, and then store the results into a similar output publication.
Both inputs and outputs would need some validity schemes, which would verify that inputs are really meant for this computation (for example, they are signed by a key embedded in a computation). Trickier is to validate that outputs are really correct outputs for a given computation. One approach is to have multiple workers run the same computation and compare the outputs, similar to what BOINC is doing, or even have much more complicated output validity schemes with more workers participating, in the extreme, all workers computing all computations and then comparing outputs.
Another approach is to use new SGX capabilities of new Intel CPUs which allow one to run code in a trusted enclave and have a verifiable statement that a particular code has run inside that enclave, producing a particular result. Verifying such statement is cheaper than running the computation multiple times. Moreover, code running inside an enclave is protected and nobody, even the operating system itself, cannot access data inside the enclave. This could allow decentralized computations where computations can operate on sensitive data as well, without a need to use homomorphic encryption. Furthermore, it allows also non-deterministic outputs because an output does not have to match outputs of other runs to be considered valid. A downside is that currently verification of statements is done in a centralized way by Intel.
Which workers execute which computations can depend on various policies as implemented by multiple computations schedulers inside the decentralized computations layer. There can be multiple computation schedulers listening for new computations and assigning them to workers based on their policies. For example, one could have a set of computers connected to the system and would execute only their own computations. Alternatively, workers could participate in a CPU sharing scheme and run computations for each other. Or one could simply be selling CPU cycles on a market on top of this stack.
Computations scheduler would take output validation schemes into the account when scheduling computations (for example, SGX-based scheme might need only one worker for a given computation, while some other scheme would require that all workers run all computations).
Analogy
To easier understand the proposed stack, you can imagine that serialized computations are something like IP packets, with payload, and source and destination addresses, and computations scheduling is something like routing layer for those packets, and a CPU sharing scheme is something like Bittorrent sharing protocol which incentivizes people to participate. Or users can just buy resources on the market.
Conclusion
To conclude. If we are serious about decentralized technologies, we should be building them as independent layers where we all reuse them and have common users. This improves how innovative we can be and how robust our technologies can be. The only missing piece is a decentralized computations layer for general computations. Instead of focusing on specialized computations (like smart contracts) we should design it for general computations and have smart contracts be just a special case.