All content is available under Creative Commons
Attribution-ShareAlike license unless specified otherwise.
Attribute by linking.
The views and opinions are not necessary of my current or
past affiliations, nor are they necessary mine.
Not everything I write or share I agree with, e.g.,
it can be hypothetical, to provoke debate, troll, play devil's advocate,
entertain half-baked ideas,
explore new lines of thought or perspectives.
Not everything I expressed in the past I agree with today.
Linking is not endorsement.
All feedback is welcome.
He/him.
Mitar's Point
Somewhere and everywhere between (computer)
science, technology, nature and (open) society.
science, technology, nature and (open) society.
Contact
Posts tagged "project"
dinit
I made an opinionated init specially for Docker containers: dinit. It supports running and managing multiple programs, their stdout and stderr, and handling signals, all in the way more suitable for Docker containers. Using it means no more resource exhaustion from zombie processes, data loss by uncleanly terminated containers, stray daemonized processes that keep running, or hidden issues because failed processes inside a container gets restarted instead of taking the whole container with them.
regex2json
I made a simple tool regex2json in Go to convert traditional text-based (and line-based) logs to JSON for programs which do not support JSON logs themselves. But the tool is more general and can enable any workflow where you prefer operating on JSON instead of text. It works especially great when combined with jq. I was inspired by this blog post.
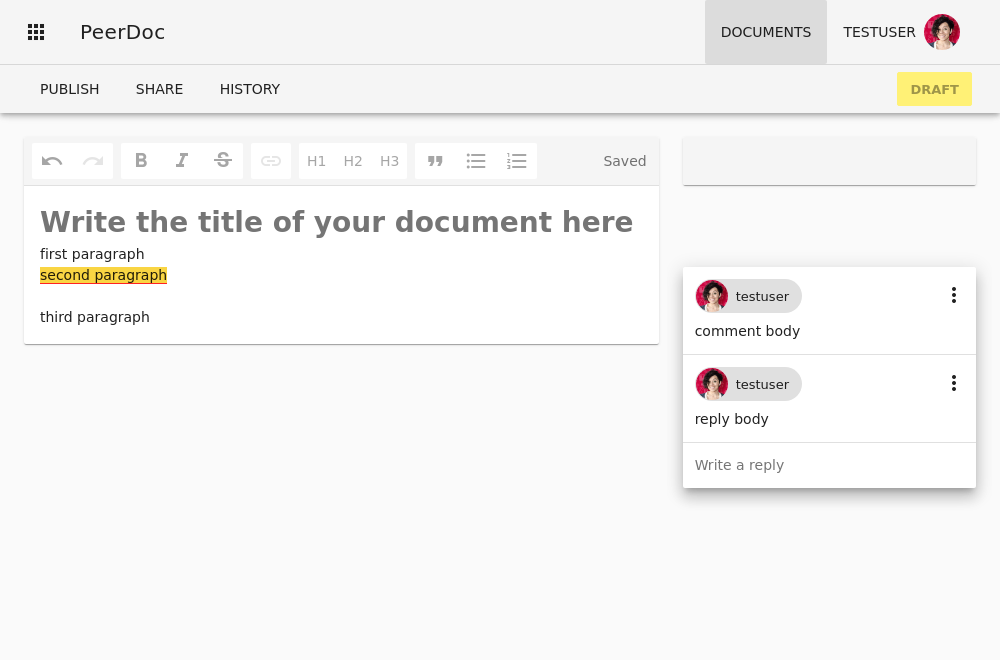
PeerDoc – Scaling real-time text editing
PeerDoc is a collaborative real-time rich-text editor with undo/redo, cursor tracking, inline comments, permissions/sharing control over documents, a change history. Things you would expect from a modern collaborative editor on the web.
But the main difference is that it combines two types of collaboration:
- real-time collaboration between collaborators on the draft of the document (push-based collaboration)
- fork and merge request style of collaboration with others, allowing collaboration to scale beyond a small group of collaborators (pull-based collaboration)
Towards Automatic Machine Learning Pipeline Design
I recently finished my PhD thesis and is now available online. Most of the code related to the thesis is available in this repository.
Reactive queries in PostgreSQL
I am a big fan of the application architecture promoted by Meteor. I like declarative programming. You describe what you want and not how and the system does the rest. Reactive programming is very similar. You define how outputs should be computed from inputs, but when is this computed and how it is composed with other computations is left to the system. So you can define what is read from the database and send to the client. And how it is read on the client and transformed and send to the UI library. And then UI library can render this data. And every time something changes, the rest gets automatically recomputed, refreshed, re-rendered.
Meteor is tightly linked with MongoDB. They developed a complex piece of technology to provide reactive queries. Reactive queries are queries which after providing initial results they also continue providing any changes to those results as input data used in queries change. While I like MongoDB, I still prefer consistency tools provided by traditional SQL databases: transactions, foreign keys, joins and triggers. They are close to declarative programming as well. You define relations between data once and then the system makes sure data is consistent. I had to implement many of those features on top of MongoDB, like my package PeerDB.
This is why I made reactive-postgres node.js package.
It provides exactly such reactive queries, but for
PostgreSQL open source database. Its API is simple, on purpose, and because it should be. You provide a query,
you get initial data, and then you get all changes. Try it out.
Proof of luck consensus protocol and Luckychain blockchain
Proof of work consensus protocol used in modern cryptocurrencies like Bitcoin and Ethereum consumes a lot of energy and requires participants to use their CPUs for mining instead of other useful work. But exactly this cost is why it is works to prevent Sybil attacks. One cannot participate in the selection of the next block without paying this cost, which makes the issue of puppet participants trying to influence block selection irrelevant, because they also have to do the work, and pay the cost.
In recent Intel CPUs a new set of instructions is available, SGX, which allows one to run code inside a special environment where even operating system cannot change its execution. In the paper we published (arXiv, Cryptology ePrint Archive) we explore consensus protocol designs using the Intel SGX technology, with the goal of making blockchain participation energy efficient, with low CPU usage, and to democratize mining so that participants can participate again with their general purpose computers (with Intel CPUs) instead of only with specialized ASICs.
nodewatcher: A Substrate for Growing Your own Community Network
A paper presenting nodewatcher.
Presentation and release of nodewatcher 3.0
Presentation and release of nodewatcher 3.0 at Battlemesh v8. Nodewatcher is an open source network planning, deployment, monitoring and maintenance platform with emphasis on community. Version 3.0 is a complete rewrite bringing modularity and extensibility.
Meteor Blaze Components
Blaze Components for Meteor are a system for easily developing complex UI elements that need to be reused around your Meteor app. Live tutorial.
My presentation of PeerLibrary at OpenCon 2014
My presentation of PeerLibrary at OpenCon 2014, the student and early career researcher conference on Open Access, Open Education, and Open Data. Slides.